The Case for a Contestable “Politician Scan”: Designing AI That Even the Loser Can Trust

Published
Modified
AI scans simplify elections but risk bias Clear rules and provenance reduce errors With oversight, even losers can trust them

The largest election year ever recorded coincides with the most persuasive media technology in history. In 2024, around half of humanity—about 3.7 billion people—will be eligible to vote in more than 70 national elections. At the same time, a 2025 study in Nature Human Behaviour found that a leading large-language model was more persuasive than humans in debate-style exchanges 64% of the time, particularly when it tailored arguments using minimal personal data. Simply put, more people are voting while the cost of influence decreases and accelerates. An “AI-assisted politician scan” that summarizes candidates’ positions, records, and trade-offs seems inevitable because it significantly reduces the time required to understand politics. However, design choices—such as what gets summarized, how sources are weighted, and when the system refuses to respond—quietly become policy. The crucial question is not whether these tools will emerge, but whether we can design them fairly enough that even losing candidates would accept them.
Why an “AI Politician Scan” Is Inevitable—and Contested, But Promising
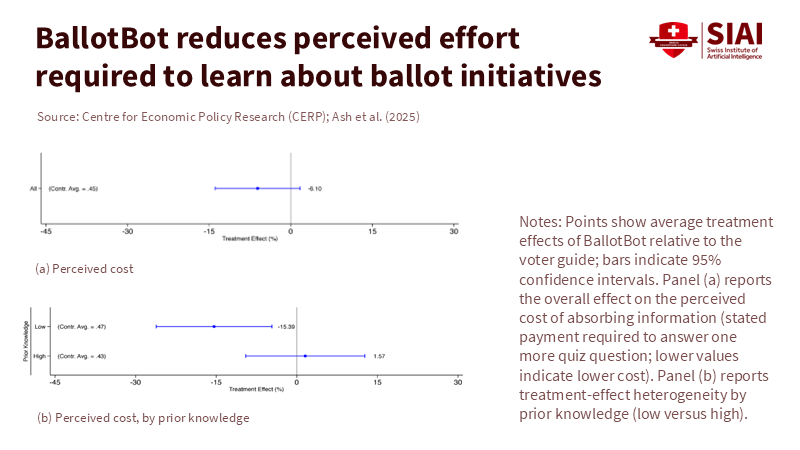
When voters confront many issues and candidates, any system that makes it easier to find, understand, and compare information will gain traction. Early evidence highlights this point. In a randomized study of California voters during the November 2024 ballot measures, a chatbot based on the official voter guide improved accuracy on detailed policy questions by 18% and reduced response time by about 10% compared to a standard digital guide. The presence of the chatbot also encouraged more information seeking; users were 73% more likely to explore additional propositions with its help. These are significant improvements as they directly address the obstacles that prevent people from reading long documents in the week leading up to a vote. However, the same study found no clear impact on voter turnout or direction of votes, and knowledge gains did not last without continued access—a reminder that convenience alone does not guarantee better outcomes.
The challenge lies in reliability. Independent tests during the 2024 U.S. primaries revealed that general-purpose chatbots answered more than half of basic election-administration questions incorrectly, with around 40% of responses deemed harmful or misleading. Usability research warns that when people search for information using generative tools, they may feel efficient but often overlook essential verification steps—creating an environment where plausible but incorrect answers can flourish. Survey data reflects public caution: by mid-2025, only about one-third of U.S. adults reported ever using a chatbot, and many expressed low trust in election information from these systems. In short, while AI question-answering can increase access, standard models are not yet reliable enough for essential civic information without strict controls.
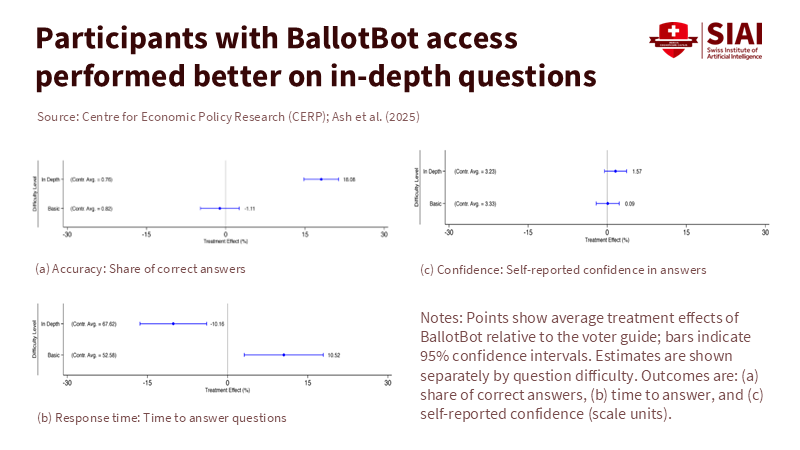
Fairness adds another layer of concern. A politician scan may intend to be neutral, but how it ranks, summarizes, and refuses information can influence interpretation. We have seen similar cases before; even traditional search-engine ranking adjustments can sway undecided voters by significant margins in lab conditions, and repeated experiments confirm this effect is real. If a scan highlights one candidate’s actual votes while presenting another’s aspirational promises—or if it disproportionately represents media coverage favoring incumbents or “front-runners”—the tool gains agenda-setting power. The solution is not to eliminate summarization; rather, it is to recognize design as a public interest issue where equal exposure, source balance, and contestability are top priorities, rather than simply focusing on user interface aesthetics.
Design Choices Become Policy
Three design decisions shape whether a scan serves as a voter aid or functions as an unseen referee: provenance, parity, and prudence. Provenance involves grounding information. Systems that quote and link to authoritative sources—such as legal texts, roll-call votes, audited budgets, and official manifestos—reduce the risk of incorrect information and are now standard practice in risk frameworks. The EU’s AI Act mandates clear labeling of AI-generated content and transparency for chatbots, while Spain has begun enforcing labeling with heavy fines. The Council of Europe’s 2024 AI treaty includes democratic safeguards that apply directly to election technologies. Together, these developments point to a clear minimum: scans should prioritize cited, official sources; display those sources inline; and indicate when the system is uncertain, rather than attempting to fill in gaps.
Parity focuses on balanced information exposure. Summaries should be created using matched templates for each candidate: the same fields in the same order, filled with consistent documentation levels. This means parallel sections for “Voting Record,” “Budgetary Impact,” “Independent Fact-Checks,” and “Conflicts/Controversies,” all based on sources of equal credibility. It also requires enforcing “balance by design” in ranking results. When a user requests a comparison, the scan should show each candidate's stance along with their evidentiary basis side-by-side, rather than listing one under another based on popularity bias. Conceptually, this approach treats the tool like a balanced clinical trial for information, with equal input, equal format, and equal outcome measures. Practically, this strategy reduces subtle amplification effects—similar to how minimizing biased rankings in search reduces preference shifts among undecided users.
Prudence pertains to the risks of persuasion and data usage. The current reality is that large language models can argue more effectively than individuals at scale, particularly with even minimal personalization. This means that targeted persuasion through a politician scan poses a real risk rather than a theoretical one. One potential solution is a “no-personalization” rule for political queries: the scan can adjust based on issues (showing more fiscal details to users focused on budgeting) but not by demographics or inferred voting intentions. Another solution is to implement an “abstain-when-uncertain” policy. Suppose the system cannot reference an official source or resolve discrepancies between sources. In that case, it should pause and direct the user to the proper authoritative page—like the election commission or parliament database—rather than guess. A third option is to log and review factual accuracy. Election officials or approved auditors should track aggregate metrics—percentage of answers with official citations, rate of abstentions, and correction rate after review—so the scan remains accountable over time rather than just during a pre-launch assessment.
A Compact Even the Losing Candidate Can Accept
What would lead a losing candidate to find the tool fair? A credible agreement with four main components: symmetrical inputs, visible provenance, contestable outputs, and independent oversight. Symmetrical inputs imply that every candidate's official documents are processed to the same depth and updated on the same schedule, with a public record that any campaign can verify. Visible provenance requires that every claim link back to a specific clause, vote, or budget line; where no official record exists, the scan should indicate that and refrain from speculating. Contestable outputs allow each campaign to formally challenge inaccuracies when the scan misstates a fact, ensuring timely corrections and a public change log. Independent oversight involves an election authority or accredited third party conducting continuous tests—using trick questions about registration deadlines, ballot drop boxes, or eligibility rules that have previously caused issues—and publicly reporting the success rate every month during the election period. This transforms “trust us” into “trust, but verify.”
None of this is effective without boundaries on persuasion and targeted messaging. A politician's scan should strictly provide information, not motivation. This entails no calls to action tailored to the user’s identity or inferred preferences, no creation of campaign slogans, and no ranking changes based on a visitor’s profile. If a user asks, “Which candidate should I choose if I value clean air and low taxes?” the scan should offer traceable trade-offs and historical voting records rather than suggest a preferred choice—especially because modern models can influence opinions even when labeled as “AI-generated.” Some regions are already adopting this perspective through transparency and anti-manipulation measures in the EU’s AI regulations, national efforts on labeling enforcement, and an emerging international treaty outlining AI duties in democratic settings. A responsible scan will operate within these guidelines by default, viewing them as foundational rather than as compliance tasks to be corrected later.
Finally, prudence involves acknowledging potential errors. Consider a national voter-information portal receiving one million scan queries in the fortnight before an election. If unrestricted chatbots fail on 50% of election-logistics questions in stress tests, but a grounded scan lowers that error rate to around 5% (a conservative benchmark based on the performance gap between general-purpose and specialized models), that still results in thousands of incorrect answers unless the system also avoids mistakes when uncertain, directs users to official resources for procedural questions, and quickly implements corrections. The key point is clear: scale magnifies small error rates into significant civic consequences. The only reliable solutions are constraints, pausing when unsure, and transparency, not just clever engagement strategies.
The initial facts will remain: billions of voters, and AI capable of out-arguing us when personalization is involved. The choice lies not between an AI-assisted politician scan and the current situation; it is between a carefully regulated tool and countless unaccountable summaries. The positive aspect is that we already understand the practical elements. Grounding in official sources enhances depth without apparent bias—consistency in templates and ranking curbs subtle influences. Pausing and ensuring provenance reduces errors. Regular testing and public metrics enable administrators to monitor quality in real time. When these elements become integrated into procurement and implementation, the scan shifts from being an unseen editor of democracy to a public service—one that even a losing candidate can agree to as a necessary step to clarify elections for busy citizens. The world's largest election cycle will not be the last; if we want the next one to be fairer, we should implement this agreement now and measure it as if our votes depend on it.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Associated Press (2024). Chatbots’ inaccurate, misleading responses about U.S. elections threaten to keep voters from polls. April 16, 2024.
Council of Europe (2024). Framework Convention on Artificial Intelligence and human rights, democracy and the rule of law. Opened for signature Sept. 5, 2024.
Epstein, R., & Robertson, R. E. (2015). The search engine manipulation effect (SEME) and its possible impact on the outcomes of elections. Proceedings of the National Academy of Sciences.
European Parliament (2025). EU AI Act: first regulation on artificial intelligence (overview). Feb. 19, 2025.
Gallegos, I. O., Shani, C., Shi, W., et al. (2025). Labeling Messages as AI-Generated Does Not Reduce Their Persuasive Effects. arXiv preprint.
Nielsen Norman Group (2023). Information Foraging with Generative AI: A Study of 3,000+ Conversations. Sept. 24, 2023.
NIST (2024). Generative AI Profile: A companion to the AI Risk Management Framework (AI RMF 1.0). July 26, 2024.
Pew Research Center (2025). Artificial intelligence in daily life: Views and experiences. April 3, 2025.
Salvi, F., et al. (2025). On the conversational persuasiveness of GPT-4. Nature Human Behaviour. May 2025.
Stanford HAI (2024). Artificial Intelligence Index Report 2024.
UNDP (2024). A “super year” for elections: 3.7 billion voters in 72 countries. 2024.
VoxEU/CEPR—Ash, E., Galletta, S., & Opocher, G. (2025). BallotBot: Can AI Strengthen Democracy? CEPR Discussion Paper 20070; and working paper PDF.
Reuters (2025). Spain to impose massive fines for not labelling AI-generated content. March 11, 2025.
Robertson, R. E., et al. (2017). Suppressing the Search Engine Manipulation Effect (SEME). ACM Conference on Web Science.
Time (2023). Elections around the world in 2024. Dec. 28, 2023 (context on global electorate share).
Washington Post (2025). AI is more persuasive than a human in a debate, study finds. May 19, 2025.




















